本文分為三個部分,介紹Agent三大痛點:知識庫+工作流程+Prompt工程。第一部分是知識庫,第二部分是工作流程,第三部分是Prompt工程。
正文:
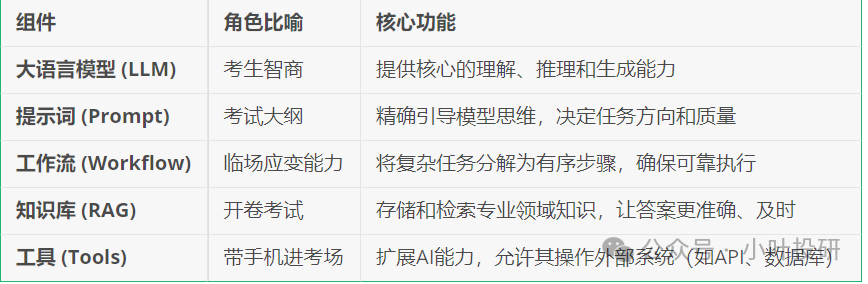
一個好的AI Agent 的大概包括五大組件:大語言模型 (LLM)是基礎計算能力,日趨標準化;工具 (Tools)是能力擴展接口,透過MCP等協議日趨標準化;知識庫 (RAG)決定知識深度與專業性,減少模型“幻覺”,是企業知識的載體;工作流 (Workflow)決定知識深度與專業性,減少模型“幻覺”,是企業知識的載體;工作流 (Workflow) 決定知識深度設計精準的提示詞、編排可靠的工作流程,以及建構和維護高品質的知識庫,是設計AI Agent的三大痛點。
一、知識庫
咱們先聊聊知識庫怎麼建。
1、知識收集
先說知識收集:你手邊的PDF、Word、PPT都算”知識原料”。例如你有個眼鏡產業的pdf報告,用minerU這種工具一掃,就能把裡面內容”扒”出來,變成系統能用的文字。就像你把一堆雜亂的書本整理成電子版,方便以後使用。
2、知識整理
知識整理是關鍵步驟:把內容切成小塊,就像切蛋糕一樣。可以按章節切,也可以按主題切,或是按固定字數切。切完後,給每塊加點”小標籤”,更方便找。例如”報告日期”、”關鍵字”,這樣以後找起來特別快。例如一份關於「專利糾紛」的報告,有以下小標籤:
標題:海外知識產權糾紛應對策略
時間:2025年9月
關鍵字:專利、法律反制、風險預警
3、知識存儲
儲存方式有講究:現在主流是存成”向量”,就是把文字變成數字向量。這樣系統能理解意思,不是死記硬背關鍵字。例如你問”眼鏡產業趨勢”,系統能知道你問的是”趨勢”,而不僅僅是匹配”趨勢”這個詞。以下三種儲存方式,對應三種知識檢索方式:
- 語意找(語意搜尋):儲存文字片段的向量表示,理解問題意思,找出最相關的。
- 關鍵字找(全文搜尋):找關鍵字匹配的
- 關聯找(圖搜尋):儲存實體及其關係,找相關聯的知識
例如問”怎麼處理客戶投訴”,語意找能定位到”客戶投訴處理指南”,關鍵字找能精準定位到”投訴處理流程”章節,關聯找還能發現”客戶服務最佳實踐”。
我傾向於採用混合儲存架構,即語義搜尋+圖搜索,對應就要使用向量資料庫(Milvus)和圖資料庫(Neo4j)。分為下面三個步驟:
① 資料模型設計:建立一個“人物關係網”+“特徵檔案庫”
想像一下,你要整理一個超級詳細的社交網絡:Neo4j(圖數據庫)就像一張巨大的“關係網”,裡面記錄著每個人(節點)是誰、有什麼特點(屬性),以及他們之間是什麼關係(邊)。例如,小明是學生,喜歡編程,認識小紅。
Milvus(向量資料庫) 則像一個“特徵檔案庫”,不為每個人保存文字描述,而是儲存他們的“數字指紋”(向量)。例如,小明的特徵可能是 [0.25, 0.8, -0.1, …](電腦能看懂的數字串),代表他的興趣、能力等。
這樣做的好處:以後既能查關係(誰認識誰),也能透過「數字指紋」快速找相似的人(例如都喜歡程式設計的人)。
② 向量化處理流程:為新資訊製作“數位指紋”
當有新資料(如一篇文章)進來時,系統會:
a.預處理:先「拆解」文章,例如分成字或句子,去掉沒意義的字(如「的、了」),就像先把食材洗切好。
b.轉成向量:用演算法(如 BERT)把這些內容變成電腦懂的「數位指紋」(向量)。這就像把一篇文章濃縮成一串特殊的密碼數字,其中相似的內容會有相似的密碼。
c.同步儲存:把這個「數位指紋」存進 Milvus,同時把文章的關鍵資訊(如標題、作者)當作屬性存到 Neo4j。這樣兩邊數據能對應上。
③ 索引優化:給資料庫加“快速查找目錄”
就像書越厚越需要目錄,數據多了也要加「索引」來提速:
a.Milvus 裡:用類似 HNSW 的演算法將「數位指紋」建立索引。想像成給所有指紋畫一張“地圖”,找相似指紋時不用一個個比對,直接按圖索驥,快很多。
b.Neo4j 裡:給常用查詢條件加索引。例如常按「姓名」找人,就給姓名建索引,這樣找「小明」就不用翻遍整個資料庫。
4、知識檢索
舉個例子你問“怎麼治療高血壓”,首先要快速找到醫學指南裡的關鍵字(比如“降壓藥”),還要理解“高血壓”和“心血管疾病”之間的關聯(比如並發症),甚至推薦“低鹽飲食”這種生活建議。
單純語意檢索可能漏掉「隱性關聯」(如高血壓和心臟病的關係),單純圖檢索可能找不到「新問題」(例如「新型降血壓藥」在圖裡沒存)。這就需要語義檢索(理解意思)和圖檢索(關聯關係)的組合拳,例如先用語義檢索找“高血壓治療方法”,再用圖表檢索找“這些方法的副作用”。具體做法:
① 語意檢索:像「找相似人」一樣找答案
把文字轉成「數字指紋」(向量),透過向量相似度找答案。例如「高血壓治療方法」和「心血管疾病治療」這兩個詞組,它們的向量會很接近,系統就能自動關聯。你問“怎麼處理客戶投訴”,語義檢索會匹配“客戶投訴處理指南”這類文檔,而不僅僅是死磕“投訴”這個詞。
② 圖檢索:像「查人際關係網」一樣找答案
把知識存成「關係網」(節點+邊)。例如「高血壓」是節點,它和「降血壓藥」「心臟病」「飲食建議」之間有邊(關係)。你問“高血壓有哪些併發症?”,圖檢索能直接跳到“心臟病”“腎臟病”這些關聯節點,還能推薦“低鹽飲食”這類關聯建議。
③ 輔助檢索手段:動態權重與預計算
a.根據問題類型調權重
不是所有問題都適合用同一種檢索方式。例如關鍵字強相關的問題(「諾貝爾獎得主名單」),可以提升關鍵字權重到0.85,直接配對「名字」;又如開放性問題(如「AI的未來趨勢」),這時候就提升語意權重,找相似主題的分析報告。在技術實作上用意圖分析模型(例如判斷問題類型)即可,即時調整語意和關鍵字的權重比例。
b.圖嵌入向量:讓圖表檢索“加速跑”
圖檢索需要遍歷節點和邊,速度慢,我們可以透過預先計算每個節點的“向量指紋”,存在向量庫解決,這在上文中也提到過。舉個例子,在社交網絡中,先預計算每個人的興趣向量(比如[0.9, 0.2, 0.7]代表喜歡編程、電影、旅遊);接著找“和小明興趣相似的人”,直接比對向量,不用遍歷整個社交關係網。
5、知識排序
排序策略主要包括:
a.多階段重排序
先用簡單演算法(如BM25)粗排,再用複雜模型(如交叉編碼器)精排
b.上下文排序
結合使用者歷史行為與即時對話內容,動態調整排序權重
c.規則乾預排序
根據業務規則(如安全攔截、時效性要求)進行最終篩選
5、知識更新
知識庫就像一個有生命的“知識倉庫”,需要持續“保鮮”和“打理”,才能保證裡面的資訊不過時、不出錯。一個好的更新機制能讓這個倉庫自動或半自動地“補貨”和“清貨”,並減少人工折騰。
① 自動偵測變化,觸發更新
系統會像「哨兵」一樣盯著知識來源(例如文件、資料庫),一旦發現變動(如上傳了新文件、更新了日誌),就自動啟動處理流程。這就類似設定了自動提醒,檔案一改,後續的解析、儲存流程就跟著運作。
② 增量更新,只處理“新貨”
為了省時省力,不需要每次都把整個知識庫重做一次。而是只處理新加的、或者有變動的部分,原來沒動的就直接保留。這就像超市補貨,只上新商品,貨架上原有的商品不動。
③ 處理版本衝突與矛盾
知識來源多了,不同版本或不同來源的資訊可能會有衝突。這時可以:
a.保留歷史版本
同一個檔案可以有多個版本,系統會標示出來,你可以選擇以哪個為主。
b.用元資料標識
在第二部分「知識整理」中,文字切塊以後,我們已經加上標籤了,我們只需要給文件打上更多標籤即可,例如生效時間、失效時間、狀態(如「已廢棄」)。查詢時,系統能透過標籤(如狀態、時間)自動過濾掉失效或過時的內容,確保你查到的都是「有效貨」。
其實,現在更時髦的知識庫搭建是微軟開發的GraphRag技術棧,但這個幾乎全程都是用大模型實現的,所以我感覺不一定可靠,或者說不像是真正的有價值的演算法。有興趣的話留言,我後面會更新一下哈。
二、工作流程
下面是三巨頭之二:工作流程。
工作流程就是Agent的“行動路線圖”,規定任務怎麼一步一步完成。舉個例子,你問“明天北京天氣”,工作流程會自動:
1.先查知識庫快取(如果昨天才剛更新過);
2、沒緩存?調天氣API工具(例如用高德介面);
3.用LLM把數據整理成人話(例如「晴,25℃,適合出門」)。
工作流程為啥關鍵?沒工作流程,Agent可能亂成一鍋粥(例如先調工具再查知識庫,浪費時間)。有了它,複雜任務變流水線——你問啥,它就按順序搞定,不用你操心。實際上,理想狀態下的工作流程非常複雜,包括了循環-反思-再行動:使用者提問 → 模型判斷需要先搜尋資料 → 搜尋後發現不夠 → 再寫一段程式碼解析 → 程式碼報錯 → 模型決定修改程式碼並重試 → 最終產生答案。這個過程可能會循環很多次,直到任務成功完成。具體循環多少回合,確實無法事先預知。舉個HR根據LinkedIn資料招募的例子:
- HR輸入
輸入:包含姓名、信箱的名單 + 需要抓取的欄位(如工作經驗、技能)。
例如:HR上傳一個Excel表,裡面一行行寫著「張三,zhangsan@example.com,需要工作經驗和技能」。
- 產生查詢詞
使用預設的模板(也可以稱為Prompt)指導LLM產生LinkedIn搜尋詞。
範例:LLM根據“張三”和“工作經驗”產生搜尋字詞“張三 軟體工程師”,避免模糊搜尋。
- 爬取數據
呼叫爬蟲工具(如Playwright)在LinkedIn搜尋該詞,抓取目標個人資料頁,自動過濾非目標使用者(例如同名的人),提取指定欄位(如「任職公司A,2020-2023」)。
- 數據處理與總結
再呼叫另一個LLM,把抓到的碎片資訊整理成簡潔總結。
範例:原始數據是“在公司A做Java開發,公司B做產品經理”,LLM總結為“資深Java開發轉型產品管理,擅長技術落地”。
- 產生個人化訊息,再發送
根據總結內容產生訊息模板,插入用戶特定訊息,接著透過LinkedIn API或模擬點擊工具自動發送訊息。
例子:
原始模板:“Hi [名字],我注意到你曾在[公司]做[職位],對[技能]有深入經驗……”
替換後:“Hi 張三,我注意到你曾在公司A做Java開發,後轉型產品管理,擅長技術落地。我司正在招募Java架構師,或許有合作機會?”
由於精力有限,下一篇文章咱們再重點介紹一下Coze工作流程的原理,在工作流程上,Coze確實是比較成熟可靠的商業化產品了。
三、Prompt工程
最後介紹一下Prompt工程。
Prompt工程就是設計AI的思維操作系統。就像你教一個新員工做事,不能只說”做這個”,得告訴他”你是誰、為什麼做、怎麼做、做成什麼樣”。
1.系統提示詞
① 角色設定
很多人寫”你是資深產品經理”,結果AI開始講行業大道理。真正好用的提示詞是”你是電商產品文案產生器”。為什麼呢?如果是人類專家會思考”為什麼”,但是機器只會執行”怎麼做”。
錯的角色設定:”你是資深電商營運專家,擅長寫產品文案”
對的角色設定:”你是電商產品文案產生器,只負責根據參數輸出100字產品描述,不添加額外解釋”
② 上下文
AI是沒有常識的,例如:
“你是智慧客服,用戶問:『為什麼我的訂單還沒出貨?’
你提供給AI的上下文:用戶訂單號碼為20231001,已支付,物流顯示’已攬收’”
這樣AI才知道”訂單已支付但物流狀態是’已攬收’,不是沒發貨”,不會答”請等待發貨”。
2、Examples:讓AI”照著做”,不是”猜著做”
寫Examples如果只放隨便幾個例子,AI可能還是胡來。關鍵不是放例子,而是讓AI”學會思考”。透過3個例子,它就記住”這樣寫是對的”。我在寫例子的時候大概有下面幾個經驗:
① 品質優先:只放正確例子,別放”可能對可能錯”的
② 亂序排列:別把對的放一起,錯的放一起
③ 涵蓋全面:不同場景都要有例子,例如:
正常查詢:”手機沒電了怎麼辦?” → “充電5分鐘,通話2小時”
異常情況:”手機進水了,還能用嗎?” → “請立即關機,勿充電”
④ 不要放過程描述,直接給結果
假設你要AI查庫存和物流,如果你這樣寫example:
你的example :
“先查庫存,再看物流,最後輸出結果”
AI的回覆
“1. 查庫存 2. 看物流 3. 輸出結果”
如果你給AI的example中有”步驟”,它就會模仿”步驟”,而不是真的去查庫存。但是工程系統需要的是結構化資料(如JSON),而不是步驟說明。下面是正確的example:
你的example:
“你是庫存物流查詢助手,只輸出JSON格式。
範例:
輸入:查詢iPhone 15庫存和物流 → 輸出:{“庫存”: “有貨”, “物流”: “已出貨”}
輸入:小米14物流狀態 → 輸出:{“庫存”: “缺貨”, “物流”: “未出貨”}
請嚴格按JSON格式輸出,不要任何其他文字
“
AI的回覆:
{“庫存”: “有貨”, “物流”: “已出貨”}
3.Output Format:讓AI老實交作業
光說”輸出JSON”,AI可能只是給你寫段話。必須用”約束+範例+重複強調”。
實際例子:
你是JSON產生器,只輸出JSON,不要任何其他文字。
範例:
輸入:iPhone 15 價格5999 → 輸出:{“name”: “iPhone 15”, “price”: “5999”}
輸入:手機沒電了怎麼辦 → 輸出:{“solution”: “充電5分鐘,通話2小時”}
錯誤範例:’iPhone 15價格5999元’ → 正確範例:{“name”: “iPhone 15”, “price”: “5999”}
請嚴格按JSON格式輸出
這樣,AI幾乎不會跑偏。我們Prompt工程往往做不好的原因,一方面我們以為AI是人覺得AI能”理解”,其實它只是”匹配模式”。或只給任務,不給框架,說”寫產品介紹”,不說”用什麼風格、什麼長度”。還有例子太簡單狀況,只給1個例子,AI沒學會”規則”。不重視Output Format,覺得”輸出隨便”,也會出現工程系統沒辦法處理的問題。
為什麼AI不按JSON輸出?
因為AI的”思考慣性”:它覺得”說人話”比較自然。你請實習生寫報告,他可能先寫”我今天做了啥”,而不是直接給結論。
有效方法:
角色定位:開頭就寫”你是JSON生成器,只輸出JSON,不解釋”;反覆強調:開頭和結尾都寫”必須輸出純JSON,不要任何其他文字
Leave a Reply