本文聚焦 AI 叢集的網路架構設計與互聯技術選擇,系統分析 AI 流量特性、叢集架構差異及關鍵互聯方案,提出 「端點調度」 與 「交換器調度」 兩大設計路徑。
一、AI 叢集的網路需求與流量特性
1. AI 叢集的核心訴求:規模、效率與彈性
隨著 AI 模型向萬億參數級演進,集群對網路提出三大極致需求:
超大規模擴展:需支撐百萬級 XPU(GPU/NPU)協同,單機櫃到跨數據中心的全場景互聯;
高效低延遲:XPU 間透過集合通信(Collectives,如 All-Gather、All-Reduce)頻繁交互參數,要求延遲通過集合通信(Collectives,如 All-Gather、All-Reduce) XPU、機架功率差異、混合負載(訓練 / 推理),避免 「單點瓶頸」 拖累整體效能(叢集效能由最慢節點決定)。
- AI 流量的四大獨特性
與傳統資料中心流量相比,AI 流量具有顯著差異,直接影響網路設計:
同步性強:訓練任務中 XPU 按固定週期交換數據,流量呈 “長突發、高同步” 特徵,易引發 “入隊(Incast)” 擁塞;
RDMA 依賴:依賴無損網路(Lossless)支撐 RDMA協議,確保資料不丟包,避免重傳導致的延遲激增;
流特性穩定:單流生命週期長(從任務啟動到結束)、速率高,且熵值低(流量路徑相對固定),傳統負載平衡策略效率不足;
可靠性轉移:AI 應用將可靠性責任轉移到網路(如模型訓練無法容忍資料遺失),需使用資料。
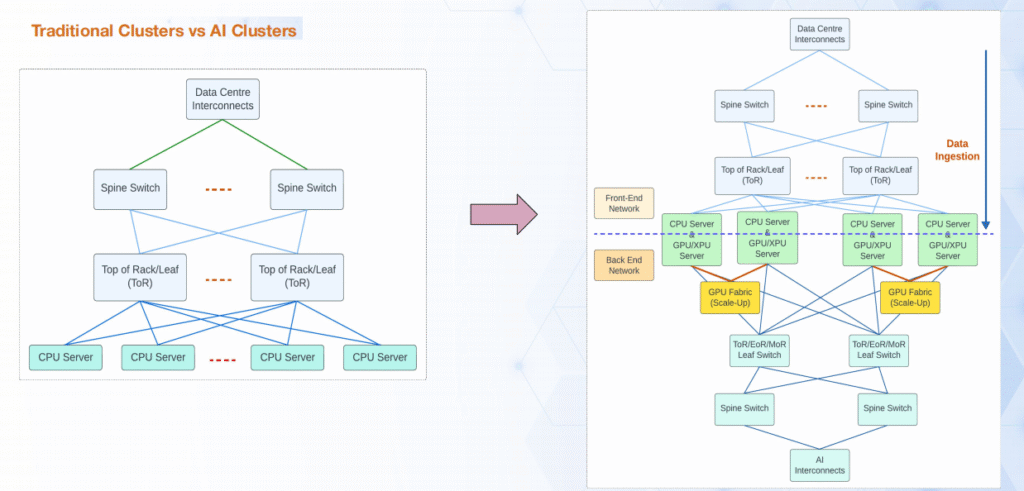
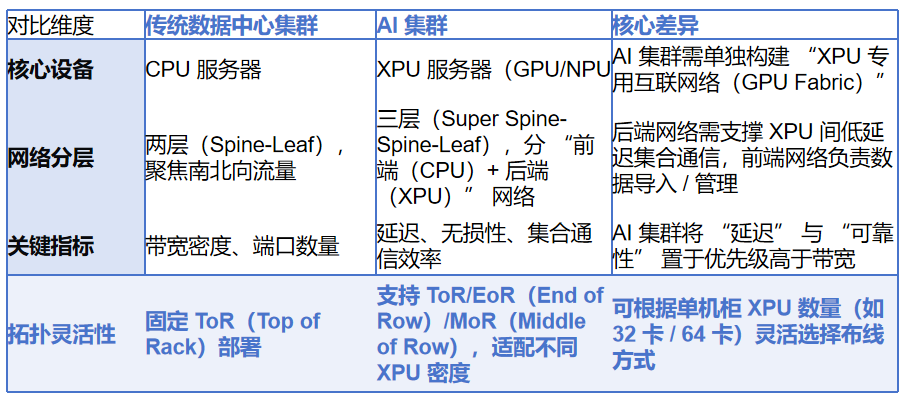
二、AI 叢集與傳統叢集的架構差異
傳統資料中心叢集以 “CPU 伺服器為核心”,網路聚焦 “資料 ingestion、儲存、運算」 的橫向互動;而 AI 叢集以 “XPU 為核心”,需區分 “前端網路(CPU 互動)” 與 “後端網路(XPU 互聯)”,架構較為複雜:
三、AI 集群的兩大核心網路設計路徑
Arista 提出兩種主流 AI 叢集網路架構,分別適應不同規模與異質需求,核心差異在於 「流量調度責任歸屬」:1. 端點調度架構(Endpoint Scheduled/NSF)
(1)核心邏輯調度責任由 XPU 端點(如 NIC/DPU)承擔,網路僅負責基礎轉發,依賴端點實現負載平衡與擁塞控制,本質是 「乙太網路原生架構的最佳化延伸」。
(2)關鍵特性拓撲與元件:採用扁平化 Spine-Leaf/Super Spine 架構,交換器僅提供高頻寬(如 800G 連接埠)與高連接埠數(Radix),無複雜調度功能;
端點依賴:NIC 需支援動態負載平衡(DLB)、自適應路由(Adaptive功能;避免單鏈路擁塞;優點:架構簡單,佈線靈活,相容於現有乙太網路生態,適合中小規模叢集(≤10K XPU);限制:NIC 廠商鎖定(需專用功能),大規模叢集中端點調度複雜度高,易出現負載不均。
- 交換器調度架構(Switch Scheduled/DSF)
(1)核心邏輯調度責任由網路交換器承擔,端點(XPU/NIC)無需複雜功能,網路透過 「訊號元交換(Cell Spraying)」 與 「信用流控」 實現無損與高效,本質是 「客製化乙太網路架構」。
(2)關鍵特性拓樸與元件:Leaf 交換器負責佇列管理、調度與信元拆分,Spine/Super Spine 僅做低功耗轉送;
引入 “虛擬輸出佇列(VOQs)” 避免隊頭阻塞(HOL Blocking);
無損機制:透過 “信用請求 – 授予協定(Credit Request/Grant)” 結合出口不溢出, PFC(優先級流控)、ECN(明確擁塞通知)實現端對端無損;
擴展能力:單系統支援 4.6K×800G 或 9.2K×400G XPU,兩級架構可擴展至 32K+ GPU,適配超大規模訓練群集; NIC),大規模下效能穩定,擁塞控制更精準;
限制:交換器硬體複雜度高,成本高於端點調度架構,佈線需匹配信元交換要求。
四、AI 叢集的拓樸與互聯技術選擇
1. 拓樸設計:多平面與分層擴展
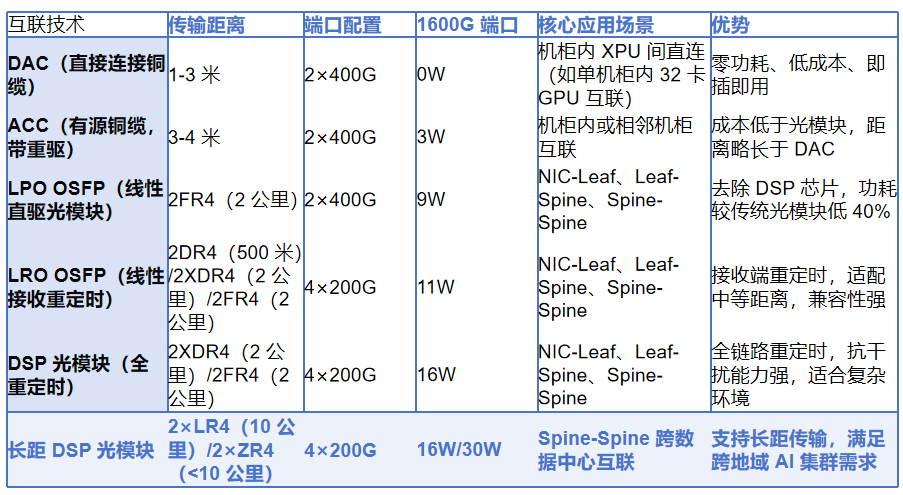
為支撐百萬級 XPU,Arista 建議 “多平面(Multi-Planar)” 架構,核心是將網路拆分為獨立平面,每個平面承擔部分 XPU 互聯,實現 “並行擴展”:平面內架構:單平面採用 Spine-Leaf 兩級架構,Leaf 連接 XPU 伺服器(ToR/EoR),Super實現跨平面互聯;平面間協同:多個平面並行工作,透過聚合層(Aggregate)互聯,避免單平面故障導致叢集癱瘓;擴展能力:單平面支援 4K-10K XPU,10 個平面可支撐 100K+ XPU,滿足超大規模訓練需求。 - 800G 互聯技術:按場景選擇最優方案
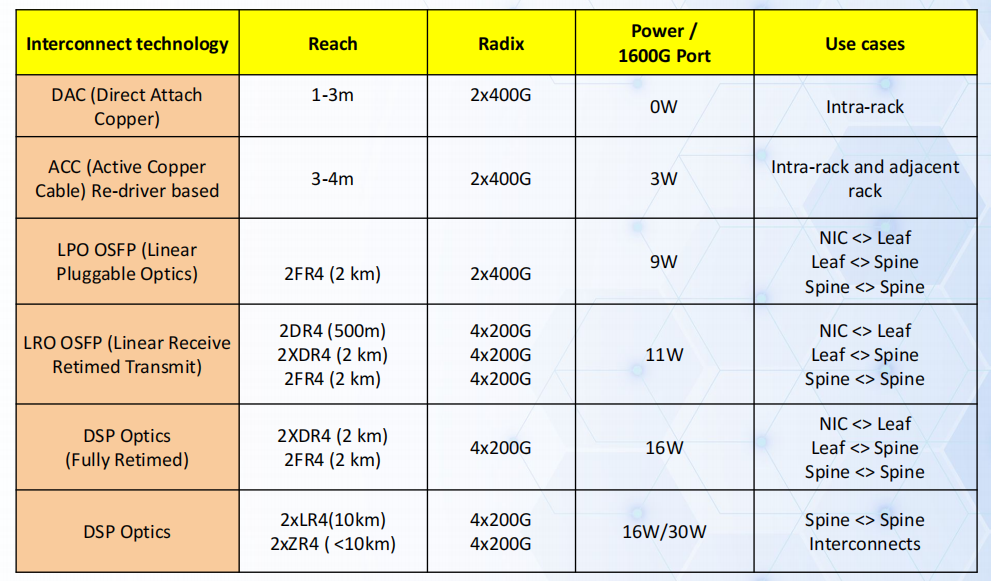
Arista 整理了 6 類 800G 互聯技術,覆蓋 “機櫃內 – 跨機櫃 – 跨資料中心” 全場景,核心差異在於傳輸距離、功耗與成本:
五、总结与未来趋势
- 核心結論架構選擇:中小規模集群(≤10K XPU)優先 “端點調度(NSF)”,平衡成本與靈活性;超大規模集群(≥32K XPU)需 “交換機調度(DSF)”,確保性能穩定;拓撲擴展:多平面架構是支撐百萬級 XPU 的關鍵,透過經壓聯組件,透過適聯瓶主聯裝工具DAC/ACC(低成本、低功耗),跨機櫃用 LPO/LRO(平衡功耗與距離),長距用 DSP 光模組(可靠度優先)。
- 未來趨勢集合通訊優化:需深入研究 All-Gather、All-Reduce 等操作對流量的影響,優化網路拓撲與調度策略;標準化與測試:推動 MPI、NCCL、RCCL 等協議的網路基準測試,建立統一效能評估系統;新興互聯技術融合:探索 UEC(Ultra Ethernet Consortium)、UALink 等新標準,進一步推動網路提升至「新進網路」。
Leave a Reply