james.zhu SIP实验室
Zoom的技術長宣布ZOOM的AI旅程中的一個重要里程碑。
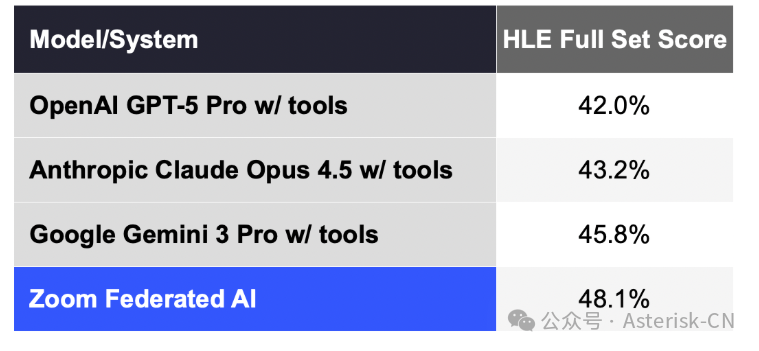
今天,我們宣布Zoom在具有挑戰性的”人類最後考試”(HLE)全套基準測試中取得了新的最先進(SOTA)成果,得分為48.1%,比之前谷歌Gemini3-pro工具集成的45.8%的SOTA結果提高了2.3%。
這項突破不僅僅是一個數字——它體現了我們從AI Companion 1.0到即將推出的AI Companion 3.0的演變,展示了與行業領導者的深思熟慮的合作如何推動創新,使每個人受益。
理解HLE挑戰 人類最後的考試(HLE)基準代表了AI最嚴格的測試之一,旨在評估模型在需要專家級知識和複雜推理能力的各種領域中的表現。
與可能依賴模式匹配的簡單基準不同,HLE要求真正的理解、多步驟推理,以及在複雜、相互關聯的問題中綜合資訊的能力。
這項基準測試由全球各地的主題專家開發,已成為衡量AI在具有挑戰性的智力任務上向人類水平表現進展的關鍵指標。
我們48.1%的成績使Zoom的聯邦AI方法在這個競爭激烈的領域中處於前沿地位。站在巨人的肩膀上 我們的成功建立在人工智慧研究社群奠定的非凡基礎上。
我們深深欽佩OpenAI的開創性工作,其GPT模型重新定義了自然語言理解和生成的可能性。谷歌的Gemini 3 Pro推動了多模態人工智慧的邊界,而Anthropic的Claude Opus 4.5則提升了我們對智慧代理能力的理解。
我們並不將這些進步視為競爭,而是將其視為合作和相互提升的機會。人工智慧的未來不在於孤立,而在於智慧協作。基準測試結果 我們在HLE全套基準測試中的表現展現了聯邦人工智慧的強大能力:
更多详情:https://www.zoom.com/en/blog/humanitys-last-exam-zoom-ai-breakthrough/?utm_source=social&utm_medium=organic-social
Leave a Reply